


En el mundo de la inteligencia artificial, los modelos de clasificación juegan un papel crucial en la toma de decisiones automatizadas. Ya sea para filtrar correos electrónicos no deseados, reconocer imágenes o analizar sentimientos en redes sociales, entrenar tu propio modelo de clasificación puede brindarte una ventaja competitiva significativa. En este artículo, te guiaremos paso a paso para que puedas desarrollar y entrenar tu propio modelo de clasificación adaptado a tus necesidades. ¡Vamos allá! 🚀
1. Define el Problema y Recolecta los Datos 📊
Antes de comenzar, es esencial tener claro qué es lo que deseas clasificar. ¿Quieres identificar spam en correos electrónicos? ¿Clasificar imágenes de productos? Una vez definido, el siguiente paso es recolectar datos relevantes y de calidad. Puedes obtener datos de fuentes públicas, generar tus propios conjuntos de datos o utilizar APIs que proporcionen la información necesaria.
2. Preprocesa los Datos 🧹
Los datos en bruto rara vez están listos para ser utilizados directamente. Es importante limpiarlos y transformarlos para mejorar la precisión del modelo. Esto incluye eliminar duplicados, manejar valores faltantes, normalizar o estandarizar los datos y, en el caso de datos de texto, realizar tareas como tokenización y eliminación de palabras vacías.
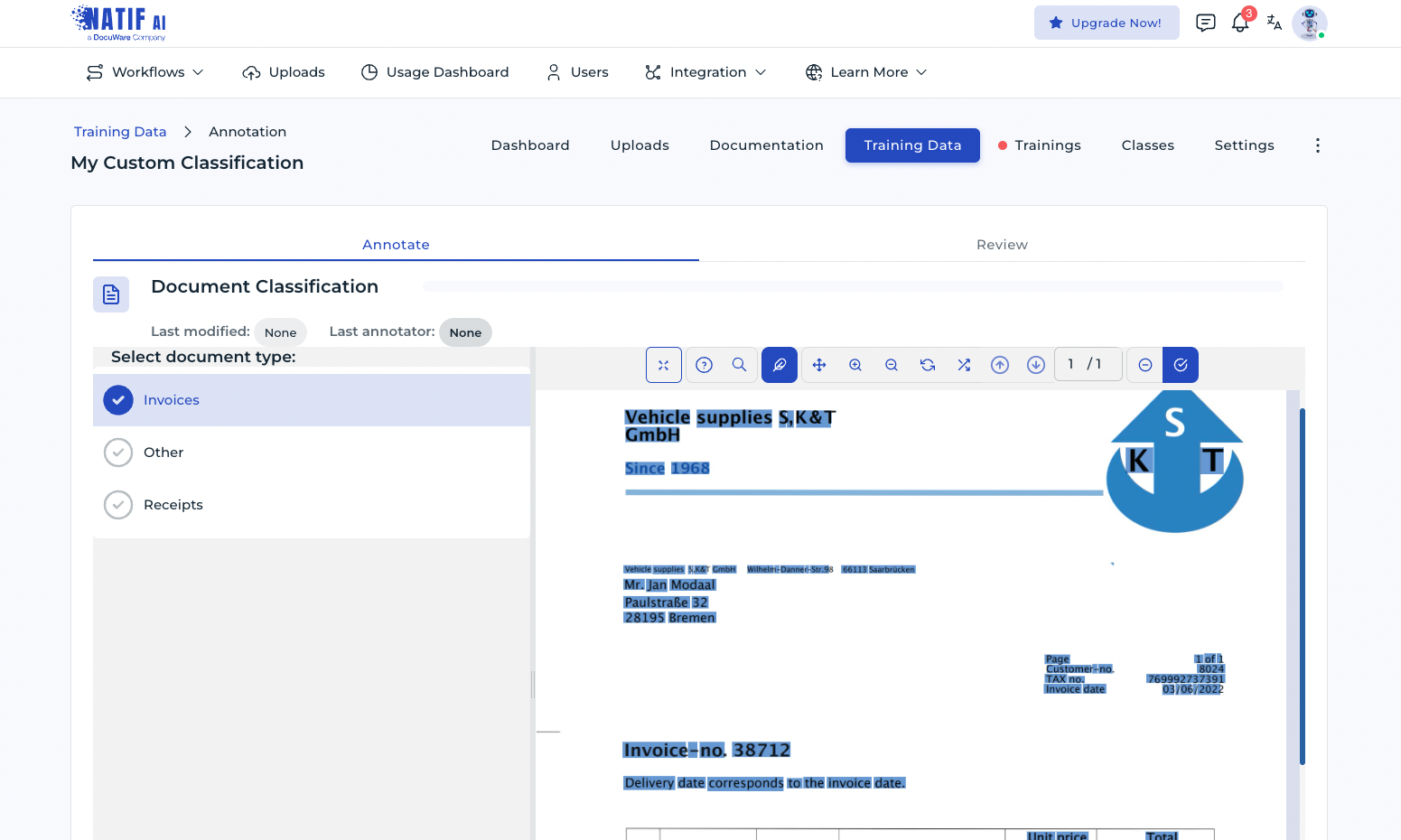
3. Selecciona el Algoritmo Adecuado 🧠
Existen diversos algoritmos de clasificación, cada uno con sus ventajas y desventajas. Algunos de los más comunes incluyen:
- Regresión Logística: Ideal para problemas de clasificación binaria.
- Máquinas de Soporte Vectorial (SVM): Eficaces en espacios de alta dimensión.
- Árboles de Decisión: Fáciles de interpretar y visualizar.
- Redes Neuronales: Potentes para manejar grandes cantidades de datos y patrones complejos.
4. Divide el Conjunto de Datos 📂
Para evaluar correctamente el rendimiento de tu modelo, es fundamental dividir los datos en conjuntos de entrenamiento y prueba. Una división común es usar el 80% de los datos para entrenar y el 20% restante para probar. Esto ayuda a asegurar que el modelo generalice bien y no simplemente memorice los datos de entrenamiento.
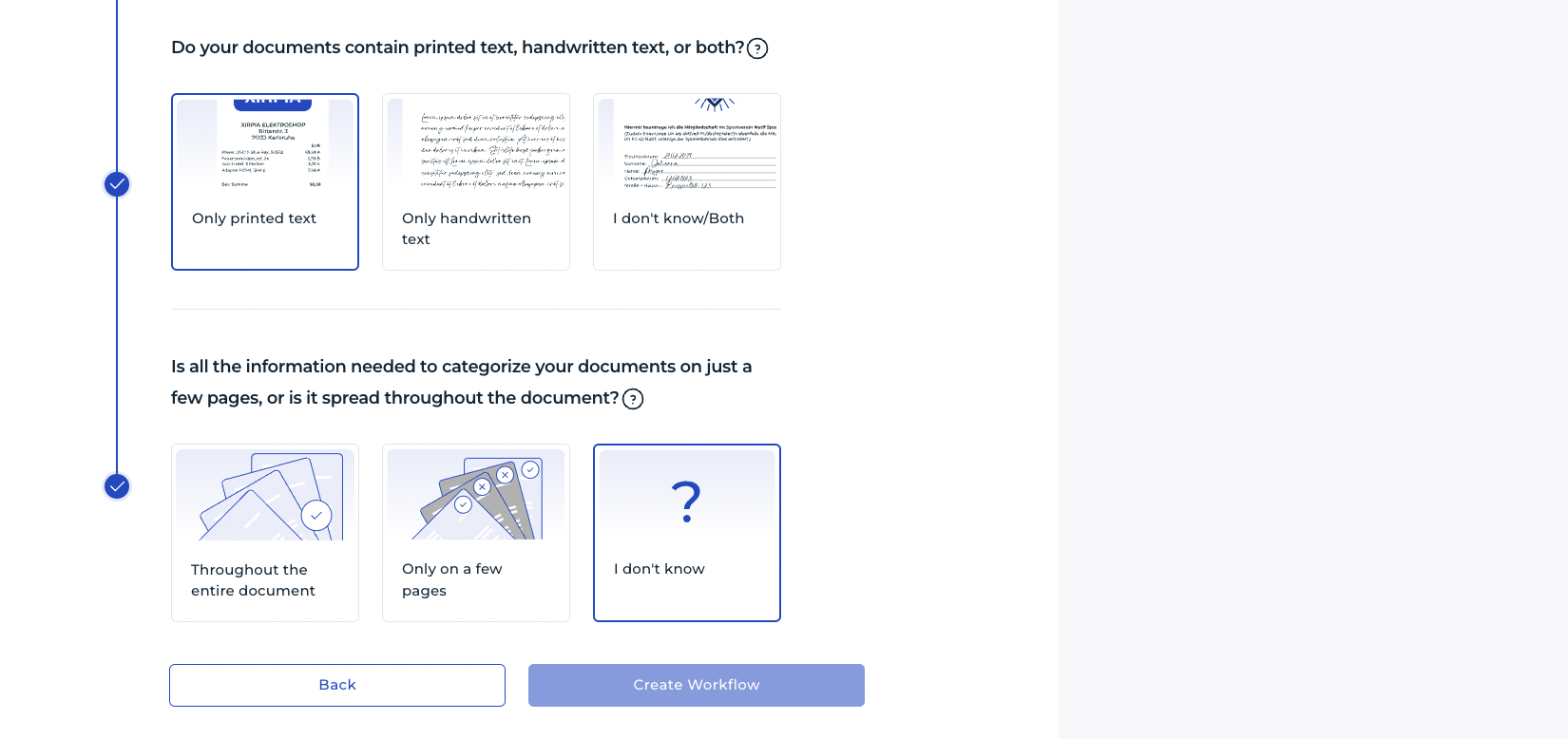
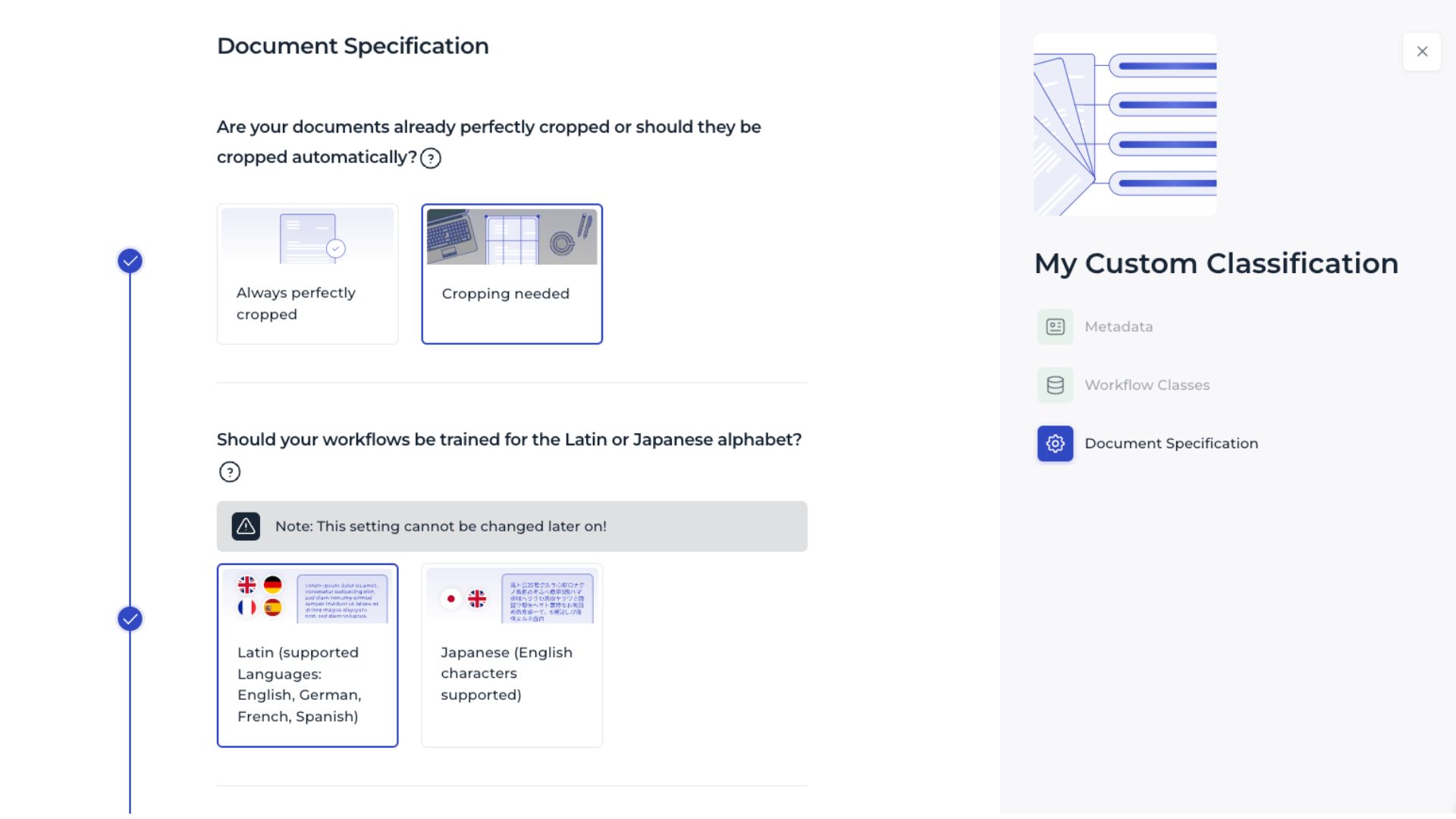
5. Entrena el Modelo 🏋️♂️
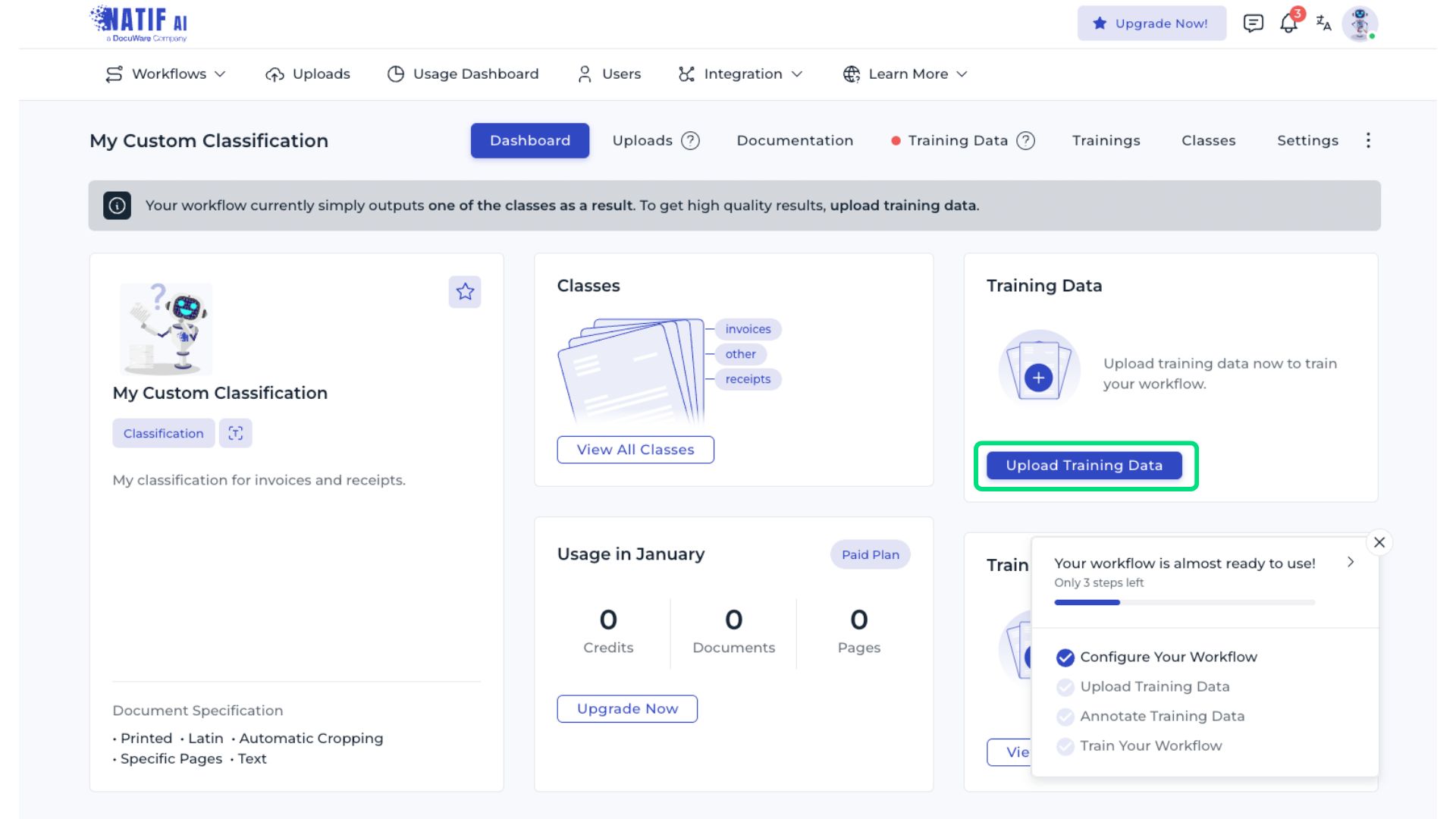
Con los datos preparados y el algoritmo seleccionado, es hora de entrenar el modelo. Utiliza librerías como Scikit-learn en Python, que ofrecen implementaciones eficientes de múltiples algoritmos de clasificación. Ajusta los hiperparámetros según sea necesario para optimizar el rendimiento.
6. Evalúa el Modelo 📈
Después del entrenamiento, es crucial evaluar el desempeño del modelo utilizando métricas adecuadas como precisión, recall, F1-score y la matriz de confusión. Estas métricas te ayudarán a entender dónde está funcionando bien el modelo y dónde necesita mejoras.
7. Implementa y Monitorea 🚀
Una vez satisfecho con el rendimiento del modelo, puedes implementarlo en un entorno de producción. Es importante monitorear continuamente su rendimiento, ya que los datos pueden cambiar con el tiempo, lo que podría requerir reentrenar el modelo periódicamente.
Recursos Adicionales 📚
Si deseas profundizar más en el tema, aquí tienes algunos recursos que podrían serte útiles:
Entrenar tu propio modelo de clasificación puede parecer una tarea desafiante al principio, pero con las herramientas y conocimientos adecuados, puedes desarrollar soluciones efectivas que impulsen tus proyectos tecnológicos. ¡No dudes en comenzar y explorar el fascinante mundo de la inteligencia artificial! 🚀🤖
CONTACTANOS PARA UNA DEMO